ABSTRACT
This Whisper Study demonstrates two “lift and shift” as organizations migrate their enterprise data warehouses to the cloud. The first is a “lift and shift” from Teradata Active Enterprise Data Warehouse on-premise to Teradata Vantage deployed in Amazon Web Service (AWS) leveraging the Teradata Everywhere license. The second is an update to near real-time product data on the web followed by a “lift and shift” from ETL jobs into Exadata to IPaaS integration storing in Amazon Redshift.
The Studies
Bayer Crop Science EDW Migration to the Cloud
- Scenario: Enterprise data warehouse migration to the cloud
- Start State: Teradata Active Enterprise Data Warehouse on premise
- End State: Teradata Vantage on AWS
- Data Size: 60-80 terabytes
- Transition Time: 6 months discovery, week move, weekend cutover
- Interview(s): July 2019
Retailer Moving to Near Real-Time Data and Cloud Data Warehouse
- Scenario: Desired near real-time e-commerce and data warehouse migration to the cloud
- Start State: Manual e-commerce site and batch Exadata-based data warehouse on premise
- End State: Near real-time e-commerce and Amazon Redshift (cloud data warehouse)
- Data Size: 2 terabytes
- Near Real-Time E-Commerce Transition Time: 1 month planning, 2 months implementing
- Cloud EDW Transition Time: 45-day pilot, 5 months lift and shift
- Interview(s): August 2019
Key Takeaways - When transferring large amounts of data, such as during a lift and shift, be sure to check your network packet size. Using a default packet size involves significant overhead creating network latency.
- Leverage IPaaS to make up for the differences between on-premise data warehouses with integrity checks and a cloud data warehouse without integrity checks. IPaaS can also accommodate data format differences.
- IPaaS templates with dynamic binding in the new world can make up for years of ETL jobs burdening older data architectures.
Migrating to the Cloud
Organizations are regularly considering migrating to the cloud, which raises the question: how difficult is it to migrate an organization’s enterprise data warehouse (EDW) to the cloud? This Whisper Study examines how two organizations succeeded in this task that often seems insurmountable. The first case remains with the same data vendor after the cloud migration. The second case utilizes a different vendor on the cloud from on premise and follows a near real-time update of quality product information to the web application, which is also discussed.
Bayer Crop Science EDW Cloud Migration

Bayer Crop Science was migrating its data warehouse to another location when they were approached to use Teradata Everywhere1 to migrate to the cloud. Teradata Everywhere is an approach that allows users the flexibility of leveraging the license on premise or in a cloud. At that point, Bayer Crop Science decided to go ahead and “lift and shift” data from the enterprise that was on premise in a Teradata appliance to Teradata Vantage on AWS, as depicted in Figure 1.
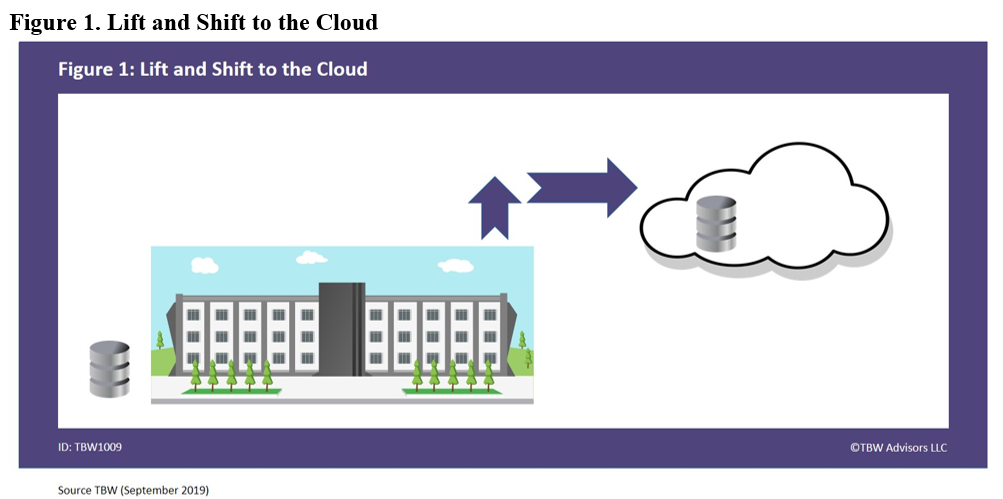
Bay Crop Science EDW Background
When the Teradata appliance was first stood up at Bayer Crop Science, it was directly connected to their ERP system. It operated near real time and included all major enterprise data from order processing to finance. Regions had their own data warehouse and data marts. Global functions leveraged the Teradata appliance since all data was already present in the appliance.
How to Move the Data
Bayer Crop Science planned to move the data in three phases. The first phase involved testing how the other two phases were going to be executed. The test had to be successful before they attempted to move development and testing environments’ data. Only after a successful test move and development move did they attempt to migrate production data.
The first hurdle was to execute a successful test data move to the cloud. The following approaches were made:
Amazon Import/Export Service2: This is a service provided by Amazon to assist clients in shipping their data to the cloud. Once received, the turn-around time to install the data is over 24 hours in addition to the transport time. Unfortunately, the ability to be down for several days was not an option. In addition, the data import did not check for errors, leaving the data unusable without extensive work.
Teradata Backup and Recovery (BAR)3: Backup and recovery is a common capability. It enables a system to quickly change from one copy of the data to another. As it is used for recovery from disasters, the second or back-up copy of the data is frequently at a different location in case the disaster was location based. Most organizations’ business continuity requires this capability to be somewhat seamless and regularly tested. This solution appeared to be straightforward until network latency issues were found while moving the data.
Hunting down the Latency Issue
When transferring data over the network, it is easy to monitor the amount of data being transferred. Unfortunately, in the early test moves, data did not seem to be flowing. Instead, Bayer Crop Science experienced significant latency in the actual data coming across the network. This problem stumped the entire team for a couple of months. The team searched high and low to try to understand why the desired data wasn’t flowing to the cloud!
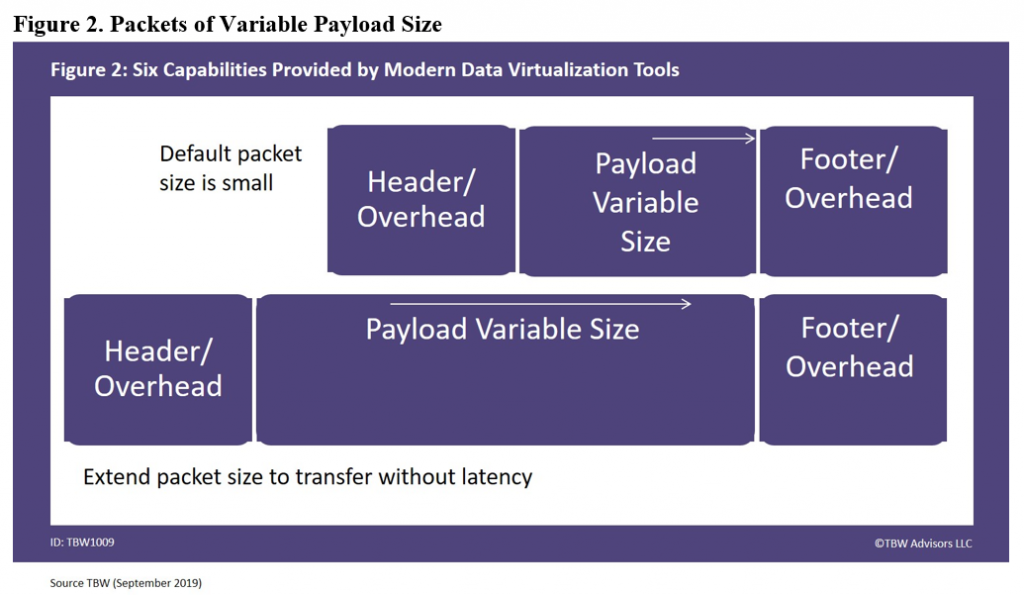
The problem causing network latency turned out to be the default TCP/IP packet size. Each packet has a header and footer with routing information and other overhead information to ensure the packet makes it to the destination. The payload is the portion where the data you are trying to transfer is put within each packet. Unfortunately, by using the default packet size, too much room was taken up in the overhead of the packet instead of the payload. By not enlarging the payload size in the packet, too high a percentage of the transferred data was the overhead vs the payload. Figure 2 depicts an example of the variable payload size within a packet. The payload can be increased up to the maximum segment size4.
The Actual Move
With the data latency issue solved, the team verified the test move. With the success of the test data move, the team moved onto Phase 2: migrating the development environment. Success again. For the third phase, they told BAR to back up their production Teradata appliance to AWS. The team then kept track of all changes since the backups were created in AWS. These final changes were the only remaining updates required in order to officially have a full data set on AWS and were migrated over the weekend. It is valuable to note that a back-up copy of the logged changes was made prior to using the logs to update the AWS data version. Once the final changes were migrated to AWS, the switch was flipped to move the system to their backups. In this scenario, the backups on AWS were the new primary home. The cloud migration was complete.
Since the migration, the corporation was bought and changed its name to the form in this document. The acquirer was 100 percent on premise, and as such, the environment is now technically hybrid. The team plans on leveraging the success from their cloud migration to evolve their new enterprise.
Retailer Moving to Near Real-Time Data and Cloud Data Warehouse

The second study involves a large retailer outside of North America that had the general business problem of being unable to update their full product catalog online for e-commerce. If a sweater only has two colors available for any size, the e-commerce site should never show all colors that were once available, only the current colors and sizes. Their solution was not real time as the website was not able to directly connect to the product information and provide complete, accurate, near real-time information. Instead, a highly manual process involving spreadsheets was used to get product information to the web application platform. Of course, once they updated their systems to real time, they desired near real-time analytics. As you might imagine, not only did their web application lack near real-time data, their data warehouse was also not in real time. Generally, it was an old-fashioned data architecture. The desire was to modernize, enable the e-commerce platform to become real time, and then transition the warehouse to near real time as well.
Phase 1: Near Real-Time Web Application
In the beginning, the web application lacked the ability to reflect current inventory levels, and the data was not fresh and accurate. In addition, the e-commerce site only represented a very small portion of their product portfolio – well below 25% of all potential products. They had a strong suspicion that representing their entire product line with near real-time data on their e-commerce site would result in revenue increases. In the beginning, the process for loading information to the web application was fundamentally manual involving a lot of Excel, as represented in Figure 3.
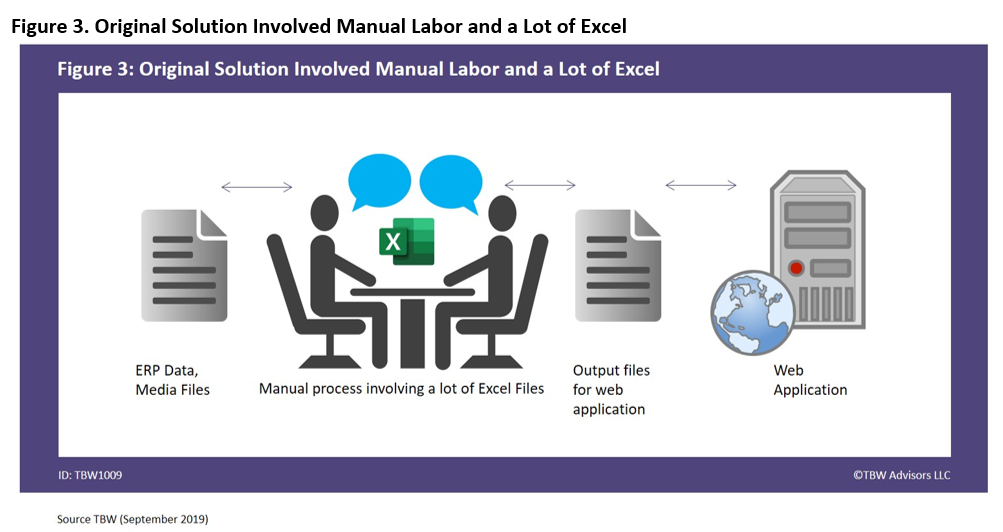
Of course, if it were easy to connect the ERP system to the web application directly, they would have likely already integrated the two systems. The first stop was to leverage Informatica’s Product Information Management Solution (PIM5) which is tailor-made to clean up your view of your product data by creating master data management (MDM) for your product data. As with most migrations and upgrades, there is always a surprise or two. In this scenario, once they had MDM, they realized that not all data sets used the same time standard, in addition to other data quality issues. By leveraging Informatica Data Quality (IDQ6), this problem was quickly and permanently solved. More important, within a quarter, they were able to successfully represent accurate inventory for 60% of their product portfolio. They were able to reach 100% online within one year of the project. The new solution is represented in Figure 4.
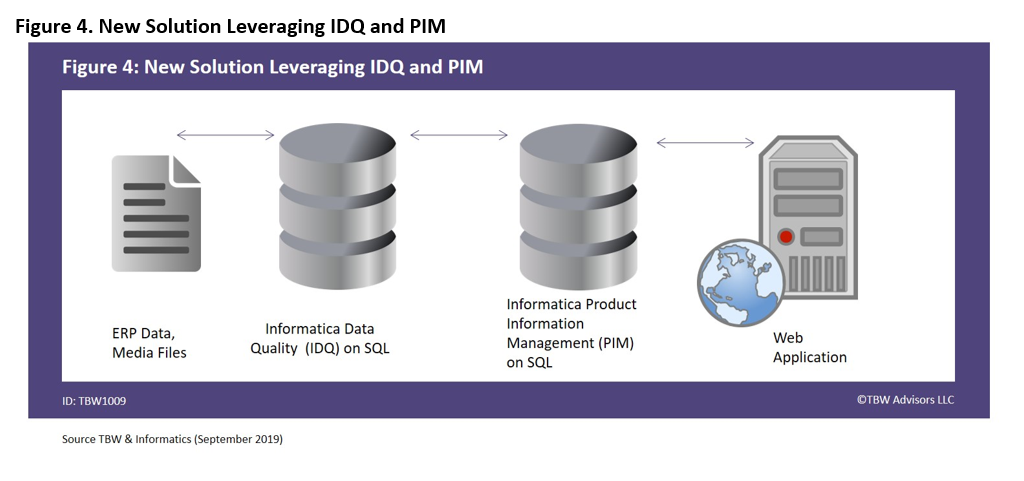
Phase 2: Near Real-Time Cloud Data Warehouse
Now that their e-commerce site represented their entire product portfolio with accurate real-time information, the business desired a near real-time enterprise data warehouse for near real-time analytic insights to match. The largest difficulty was estimating how much work everything was actually going to take to accomplish the migration. Their existing data warehouse was an Exadata, on-premise warehouse they started creating 10 years ago. Like most data warehouses, their ETL developers were busy constantly adding new data combinations to the warehouse for the business.
The challenge was how to capture and reflect all these ETL jobs that took 10 years to create.
To address the differences and accomplish the migration with all ETL jobs represented without spending 10 years on the task, the team decided to leverage Informatica’s IPaaS (Integration Platform as a Service) solution, known as Informatica’s Intelligent Cloud Services (IICS7). Next, they leveraged IPaaS templates to represent the ETL jobs. These templates enable dynamic binding of specific jobs to the templates. Thus, the templates were simply called with the data set needing that template’s represented data transformation. Now, a single template could represent a thousand different ETL jobs from the old data warehouse. In addition, the use of IICS allowed the IT team to confirm success when data was transferred, as data integrity was not provided by Amazon Redshift.
To accomplish the lift and shift, each data source was first connected to the IPaaS platform. Next, the dynamic binding of the templates was used to create the new data warehouse for those data sets. In the beginning, they prototyped and tested a single topic over 45 days. The new solution was in the cloud and provided a continuous flow of data, thus enabling near real-time analytics. Not a single data model had to change. The new EDW being tested in the cloud ran concurrently with the on-premise, soon-to-be-retired EDW. This gave the business and IT time to verify the plan was working, and the new EDW was as expected.
After the first successful topic was in the new data warehouse, it took the team another five months to finish the “lift and shift.” No redesign of data models was required. In order to efficiently accomplish the “lift and shift,” multiple IPaaS accounts were leveraged, providing additional bandwidth for the project.
TBW Advisors Recommended Reading
“Conference Whispers: Informatica World 2019”
“Whisper Report: Digital Transformation Requires Modern Data Engineering”
“Whisper Report: Six Data Engineering Capabilities Provided by Modern Data Virtualization Platforms”
Citations
- https://www.teradata.com/Resources/Executive-Briefs/Teradata-Everywhere
- https://aws.amazon.com/blogs/aws/send-us-that-data/
- https://www.teradata.com/Products/Hardware/Backup-And-Restore
- https://en.wikipedia.org/wiki/Transmission_Control_Protocol#Maximum_segment_size
- https://www.informatica.com/products/master-data-management/product-information-management.html
- https://www.informatica.com/products/data-quality/informatica-data-quality.html#fbid=ez3JEKts8Pe
- https://www.informatica.com/products/cloud-integration.html

©2019-2024 TBW Advisors LLC. All rights reserved. TBW, Technical Business Whispers, Fact-based research and Advisory, Conference Whispers, Industry Whispers, Email Whispers, The Answer is always in the Whispers, Whisper Reports, Whisper Studies, Whisper Ranking, The Answer is always in the Whispers, are trademarks or registered trademarks of TBW Advisors LLC. This publication may not be reproduced or distributed in any form without TBW’s prior written permission. It consists of the opinions of TBW’s research organization which should not be construed as statements of fact. While the information contained in this publication has been obtained from sources believed to be reliable, TBW disclaims all warranties as to the accuracy, completeness or adequacy of such information. TBW does not provide legal or investment advice and its research should not be construed or used as such. Your access and use of this publication are governed by the TBW Usage Policy. TBW research is produced independently by its research organization without influence or input from a third party. For further information, see Fact-based research publications on our website for more details.