Published to clients: July 23, 2025 ID: TBW2084
Published to Readers: July 24, 2025
Published to Email Whispers: TBD
Analyst(s): Dr. Doreen Galli
Photojournalist(s): Dr. Doreen Galli
ABSTRACT:
“Organizations can implement zero-trust security without disrupting user experience by prioritizing frictionless authentication, especially biometrics, and enforcing least-privilege access through dynamic policies. Understanding user context and behavior enables informed decisions that preserve continuity. Self-service access tools reduce delays, while streamlined verification processes minimize frustration. With thoughtful planning and clear communication, zero trust can enhance both security and usability, ensuring users access only what they need—when they need it—without unnecessary barriers. This report includes insights from executives and technologists at CyberSolve, Lumos, Imprivata, Simeio, Panani, Keyless, Oasis, Apono, Omada, and Cubeless, quoted throughout the discussion.”
Target Audience Titles:
- Chief Information Security Officer, Chief Technology Officer, Chief Digital Officer, Chief Information Officer
- Chief Product Officer, Chief Experience Officer
- IAM engineers, Security Architects, DevSecOps Engineers, UX Designers, IT Ops Managers, Application Security Architects
Key Takeaways
- Use biometric authentication to streamline access and reduce friction for users.
- Apply least-privilege policies with dynamic adjustments to maintain secure, appropriate access.
- Enable self-service access changes to minimize delays and improve user experience.
- Understand user context and behavior to make informed, non-disruptive security decisions.
How can organizations implement zero-trust security without disrupting user experience?
We took the most frequently asked and most urgent technology questions straight to the Technologists gathering at Identiverse 2025 held at Mandalay Bay in Las Vegas. This Whisper Report addresses the question regarding how can organizations implement zero-trust security without disrupting user experience?
What is the desired user experience?
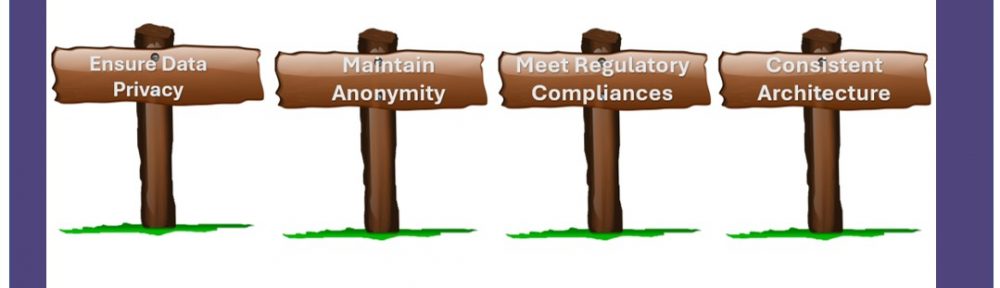
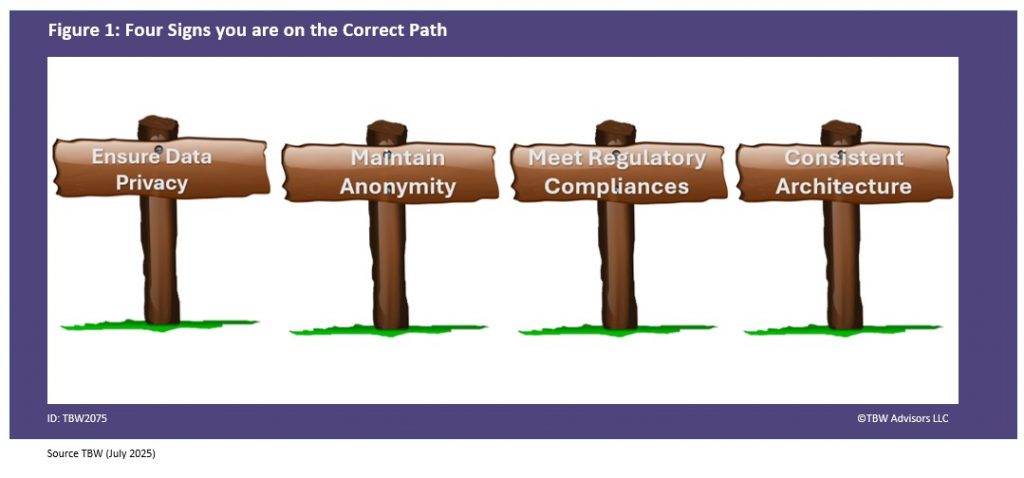
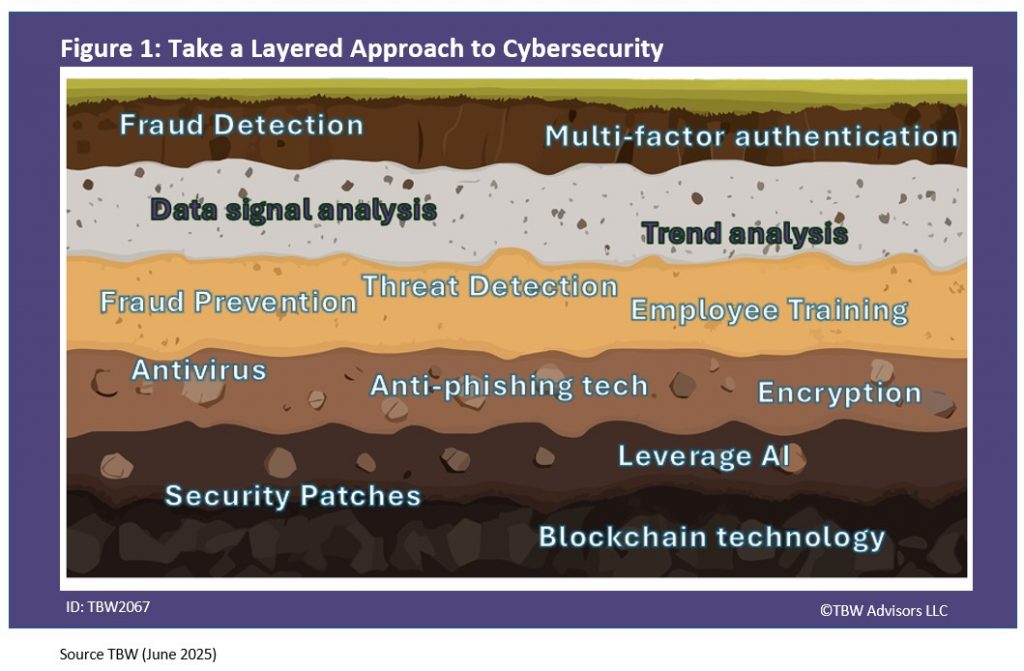
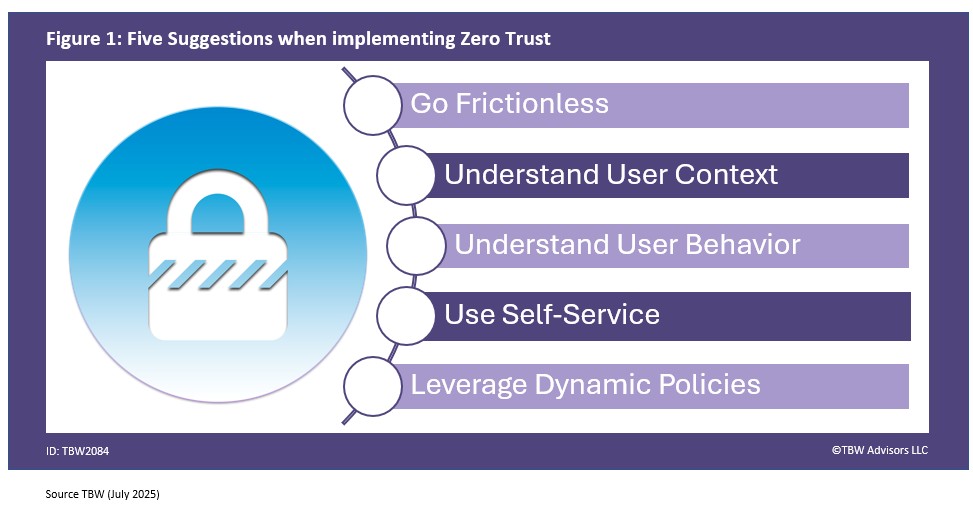
At the end of the day, the goal is, as Imprivata’s Diron Chai put it, “authentication and visibility and control to making sure that you know the right people are accessing the data whether remotely or within the organization in terms of their role and their functionality and then be a being able to understand who’s in the system when and why that all ladders up to a zero-trust architecture that we’re able to bring forth in a full architecture.” Reaching this goal won’t be easy but as Simeio’s Octavio Lopez emphasized, “There’s a lot of communication that needs to happen and that’s something that we help a lot of our customers with.” A lot of communication and planning with the customers’ experience kept in mind. Here are five suggestions attendees at Identiverse offered also depicted in Figure 1.
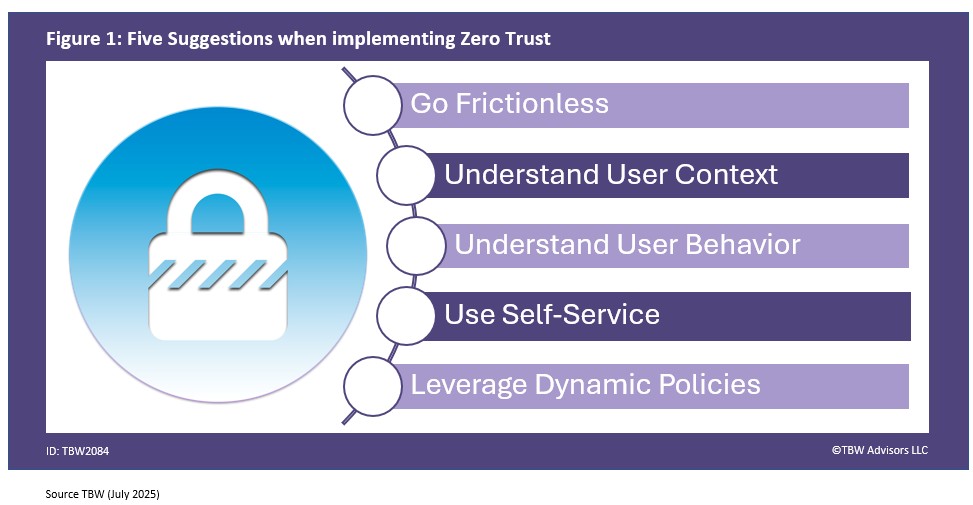
1. Go Frictionless with Bio
One common suggestions to deploy biometric based identity and access management solution. As Panani’s Jim Harris suggested, “make the authentication of your customer as frictionless as possible a one-time identity verification process establishes that customer in the future they present a simple credential match their biometric information to the information stored in the credential that they own and control making it a very frictionless fast way to authenticate with your customer.” And this is something Alex Jones from Keyless can also agree with! “going to pitch biometrics this is the fastest way to prove who you are effectively implementing zero trust.”
2. Understand User Context
Guy Feinberg at Oasis suggests that understanding the user context is the winning approach. He started by simply asking “Are you familiar with the scream test?” For those of you not familiar, one not uncommon method in IT to understand how a resource, in this case an identity, is used by disconnecting or unplugging the resource and see who screams. Feinberg went on to further explain, “when you want to understand what’s this identity is used for so what you do you decommission it and just see who’s at the open space is screaming that something is broke. We do we help you construct all the context around the consumption of that identity so you can see the full picture before you’re taking actions so you’ll have informed actions deciding do we need this type of identity now uh should we change the permission should we decommissioning it completely all without disrupting the workforce and making sure that business continuity stays on and nothing is disrupted aspects of this.”
3. Understand User behaviour
Beyond the context of what the user is using, Imprivata’s Diron Chai recommends also understanding the how and the when. “ Being able to inject simple multifactor authentication into the environment at the local level also being able to track the behavior of credentials of people accessing like Windows endpoints as an example or mobile devices and be able to have the analytics to show utilization of the endpoint but also who what when was accessed within that session.”
4. Use Self-Service
To maintain the best user experience, Apono’s Ofir Stein recommends getting the human out of the loop. “you keep the user experience by allowing self-serve in your organization to provide access changes combine these two and you actually provide zero trust to all of the resources.”
5. Leverage Dynamic Policies
Omada’s Craig Ramsay highlighted the potential behind dynamic policies. “By using dynamic and continuous policies to make sure that their access is appropriate and it’s always at that level of least privilege and then it’s granted, when they join the organization, and as they move around the organization, and it stays appropriate.” It’s always nice when your privileges keep up with organizational changes – without human intervention or manual configuration.
In Conclusion
As Cubeless’ Treb Ryan concluded, “I find zero trust has greatly enhanced our user experiences and greatly made my job easier in the old days where there’s systems where you had to figure out which networks could connect or who would have access to what particular piece it was a nightmare.”
Finally Lumos’s Janani Nagarajan reminded all, “not just in the networking layer not just in the app layer but a critical layer for us is identities because that’s where the workforce the humans the employees the contractors the vendors your customers are actually interacting with the apps.” Identities is the key to minimizing friction for the users in zero trust. If your organization is implementing a zero trust architecture and want to ensure you are on the right track, remember to book an inquiry.
Related playlists & References
- Whisper Report: How can organizations implement zero-trust security without disrupting user experience?
- Conference Whispers: Identiverse 2025
- Conference Whispers: Identiverse
- Conference Whispers: Identiverse 2024
Corporate Headquarters
2884 Grand Helios Way
Henderson, NV 89052
©2019-2026 TBW Advisors LLC. All rights reserved. TBW, Technical Business Whispers, Fact-based research and Advisory, Conference Whispers, Industry Whispers, Email Whispers, The Answer is always in the Whispers, Whisper Reports, Whisper Studies, Whisper Ranking, Whisper Club, The Answer is always in the Whispers, and One Change a Month, are trademarks or registered trademarks of TBW Advisors LLC. This publication may not be reproduced or distributed in any form without TBW’s prior written permission. It consists of the opinions of TBW’s research organization which should not be construed as statements of fact. While the information contained in this publication has been obtained from sources believed to be reliable, TBW disclaims all warranties as to the accuracy, completeness or adequacy of such information. TBW does not provide legal or investment advice and its research should not be construed or used as such. Your access and use of this publication are governed by the TBW Usage Policy. TBW research is produced independently by its research organization without influence or input from a third party. For further information, see Fact-based research publications on our website for more details.