Join us for “Public is Private – Confidential Computing in the Cloud,” featuring Mike Bursell from the Confidential Computing Consortium and Manu Fontaine, founder of Hushmesh. This event will delve into the transformative potential of confidential computing for cloud environments. Aimed at CIOs, CTOs, enterprise architects, solution architects, and technical product managers, the discussion will cover how confidential computing enhances data security and privacy, even during processing. Learn about real-world applications, challenges, and future trends in this critical technology. Don’t miss this opportunity to gain insights from industry leaders and explore how to leverage confidential computing for your organization’s success.
Research Code TBW2071
Moderator: Dr. Doreen Galli, TBW Advisors
Doreen Galli
Chief of ResearchTBW Advisors LLC
Dr. Doreen Galli is the Chief of Research at TBW Advisors LLC. She’s led significant and measurable changes as an executive at IBM, DPWN, Dell, ATT, and most recently Microsoft. Dr Galli was Chief Technology and Chief Privacy Officer in Azure’s MCIGET. Gartner recognized Dr. Galli as an expert in data ingestion, quality, governance, integration, management, and all forms and analytics including sensor data.
Mike Bursell is the Executive Director of the Confidential Computing Consortium, having been involved since its foundation in 2019, and Co- chair of the OpenSSF’s Global Cyber Policy working group. He is one of the co-founders of the open source Enarx project and was CEO and co- founder of the start-up Profian. He has previously served on the Governing Boards of the CCC and the Bytecode Alliance and currently holds advisory board roles with various start-ups. Previous companies include Red Hat, Intel and Citrix, with roles in security, virtualisation and networking. He regularly speaks at industry events in Europe, North America and APAC and has a YouTube channel dedicated to cybersecurity education. Professional interests include: Confidential Computing, Cyber Policy, the EU Cybersecurity Resilience Act (CRA), Linux, trust, open source software and community, security, decentralised and distributed systems, Web3, blockchain. Mike has an MA from the University of Cambridge and an MBA from the Open University, and is author of “Trust in Computer Systems and the Cloud”, published by Wiley. He holds over 100 patents and previously served on the Red Hat patent review committee.
Speaker Profile
Manu Fontaine
CEOHushmesh Inc
Manu Fontaine is the Founder and CEO of Hushmesh, a dual-use Public Benefit cybersecurity startup in the Washington DC area. The company believes that people need safe code and authentic data, just like they need clean water and stable electricity. To deliver this, Hushmesh leverages Confidential Computing to develop and operate “the Mesh”: a global information space, like the Web, but with universal zero trust and global information security built in. Secured by the Universal Name System (UNS) and the Universal Certificate Authority (UCA), the Mesh provides global assurance of provenance, integrity, authenticity, reputation, confidentiality, and privacy for all information within it, at internet scale. Hushmesh is a NATO DIANA Innovator startup.
Dr. Roy Fune
Cannot make it live? Register and submit your question. The answer will be in the video on TBW Advisors’ YouTube Channel.
NO AI note takers allowed. Event copyrighted by TBW Advisors LLC.
Published to clients: April 14, 2025 ID: TBW2070 Published to readers: April 15, 2025
Published to Email Whispers: July 16, 2025
Publicly Published with video edition: July 16, 2025
Analyst(s): Dr. Doreen Galli
Photojournalist(s): D. Doreen Galli
Abstract:
After over 40,000 steps, 20 flights of stairs, 8 Vegas Loop rides, 140 minutes of video content spanning education sessions, main sessions and exhibition highlights, our coverage in NAB Show 2025 closes. NAB Show 2025 hosted 55,000 attendees with 26% from 160 countries and 53% being first timers. Various vendors showcased AI-driven media solutions, storage innovations, and advanced workflows. Key technologies included AI for speech translation, video captioning, media format transformation, and virtual production. The event emphasized the importance of secure media storage and collaboration tools, with a focus on AI-enhanced search and metadata creation. Next year’s conference will be held at the Venetian in Las Vegas.
Data storage, data virtualization, identity and access management, networking, cloud computing, hybrid computing, AI vision and audio, metadata, compression and search were all popular technologies found within the solutions.
Cautions
This year’s NAB Show featured an alarming trend for those with corn allergies. Specifically numerous booths in every hall were popping corn throwing the corn protein into the air. Studies show up to 6% of the population potentially have such an allergy with some segments of the population measuring at 15%. Perhaps the LVCC should consider restricting such items in booths for future events.
Just because a storage solution holds your media and makes it easy to access does not mean it is secure and appropriate for the intellectual property for which it is used. Identity and access management must be a part of the storage solution.
While not unique to the Media industry, most data storage solutions have no method to keep track of all the various copies created of a given file therefore potentially leaving the door open for information leaks or data thefts.
Despite also catering to the growing creator economy, ad servers for social media could not be found at this event.
While at NAB Show, we conducted research for three forthcoming Whisper Reports for our clients. The playlists are unlisted but available and will eventually fill in with the video version of the report so you may wish to bookmark these playlists.
NAB has a full schedule of sessions and educational talks for attendees. Main stage in West Hall always has some of the biggest headliners. This year we were able to capture DJ Delilah’s story that she shared as she won her award. It was interesting that early in her career that her merit of achieving exceptional ratings with the audiences was rewarded with a layoff. Main stage also featured an interview with Stephen A. Smith who recently signed the largest contract for a sports commentator that wasn’t a pro-athlete.
We were also able to briefly capture two training sessions by the ever-engaging Luisa Winters. The first session taught drone pilots how to get the best shots to make amazing content. Wishing to learn more about drones and running a drone business? The answer is in our coverage of the commercial drone event, Conference Whispers: CUAV Expo. The second session by Luisa Winters was her event on additional methods to monetize YouTube. Unfortunately, what we captured seemed to be the same advice commonly found online.
Many vendors also had specialized stages such as this partner talk on the AWS Stage. This session focused on the AI content delivery workflow for a multimodal media stack. Finally, we captured the main stage event featuring the Bluemoon AI use case with Dell and NVIDIA on the topic of AI Advanced workflows. The big advice was to train your models locally.
One of the largest problems found in media is where to put all the media! Media is not only voluminous, but it is the Intellectual Property that gives media companies value. The first problem is where to store it so those that need to work with it can. Strada agents allow one to share their hard drive with collaborators turning it into a private cloud. Studio Network Solutions, SNS, gave us an overview of the various methods it enables media professionals to share their media storage for collaboration. As a word of caution, just because a product is at a conference and organizations use it does not mean it is secure. Particularly, there was an alarming lack of identity and access control technology protecting many media storage solutions. For more research on this topic see Conference Whispers: Identiverse.
Some of the solutions exhibited adds in AI for additional capabilities. For example, Axle.ai works with your storage BUT adds AI and search capabilities so one can maximize monetization of their content. Likewise, Eon Media also focuses on adding value to raw media assets leveraging various forms of AI to create the metadata to enable such powerful searches. Interestingly, their solution also enables and facilitates the licensing of such content for the full digitization to monetization spectrum. There was an abundance of solutions that applied AI to your data in your storage as well. For example, Magnify immediately searches your live video including sports video adding critical metadata to the field to reduce production costs and increase content usability.
The next largest group of technologies involves those that go beyond storage or storage and search into the production workflows. TBW Advisors LLC is excited to share that we were able to capture a demo of Latakoo, popular in end-to-end workflow in broadcasting. Furthermore, we had an exclusive interview with Latakoo’s Founders right before they found out they won Best in Show NAB25! This award recognizes their generative video coding to transcribe live video.
Dell had a large display sharing all their latest and greatest in hardware, software, and solutions including those with some of their biggest partners. Dell has always been known for their ability to understand what is required to scale out – something the crowd really seemed to appreciate at NAB. Simple and easy was the goal with the new capabilities highlighted by Ross. Where the solution leverages their components or an industry standard, just drag and drop into the workflow and you are set. As with
While many different terms are used to describe the capabilities derived, the base functionality of many solutions involved artificial intelligence analysis of speech. From the video owner’s perspective, they often seek to have the video translated from one language to another. From the business’ perspective this is called localization. YellaUmbrella provides a pay-as-you-go translation capability for all your content. If you want the video to not only have its sound in another language but attempt to make it look like they are speaking it, also known as dubbing, DeepDub supports 130 languages and is one of the solutions you should evaluate. Another AI use case with speech is to provide in-room captioning for live events. This capability is critical for those seeking inclusive events and is available via MediaScribe.
Additional technologies we found include the critical capability of changing formats – Europe and USA do not use the same formats. Broadcast and streamers do not use the same formats. Cinnafilm is known for high quality media transformations. Cinnafilm’s flagship product, Pixelstrings can even make something 1080p to 4k! If the only transformation you are seeking is clipping it into shorts along with some intelligent search, Opus clips was in the creator’s lab. Another technology from the creator’s lab is the amazing ability to create a 3d augmented reality virtual background by AR Wall. Nominated for product of the year, AR Wall also offered a package with Sony for a huge screen to install for its realization. Keeping on the theme of virtual production, Riverside offers virtual podcast capabilities. Interestingly, all recording is executed locally in order to remove any network delay or contamination in the media. Last but not least, for all those editors and producers using these amazing products, there is KB Covers and Keyboards. Mac or windows or even laptops, editor or producer tools or even analytics, CRM or ERP tools – KB Covers and Keyboards vast array is likely to have a keyboard or cover to assist.
NAB Show 2026 conference will once again be held in Las Vegas, Nevada April 18-22, 2026.
*When vendors’ names are shared as examples in this document, it is to provide a concrete example of what was on display at the conference, not an evaluation or recommendation. Evaluation and recommendation of these vendors are beyond the scope of this specific research document. Other examples products in the same category may have also been on display.
Business agility is a must during these pandemic times. Business agility requires data-driven decisions. Data-driven decision making requires data agility and the modernization of data management to enable business-led analytics. The most common, successful, and scalable data management modernizations involve data virtualization, IPaaS, and data hub technologies to provide a data layer.
Copy data management solutions are being added to architectures to address the demands of CCPA and GDPR. Copy data management is a capability available as a stand-alone data management tool, as well as provided within data virtualization platforms. Advantages of copy data management discussed in this research include the ability to stop orphan data copies, eliminate extra storage costs and keep copies up to date. Advantages discussed also include the ability for copies to be kept equal to each other, simplified governance and accelerated development.
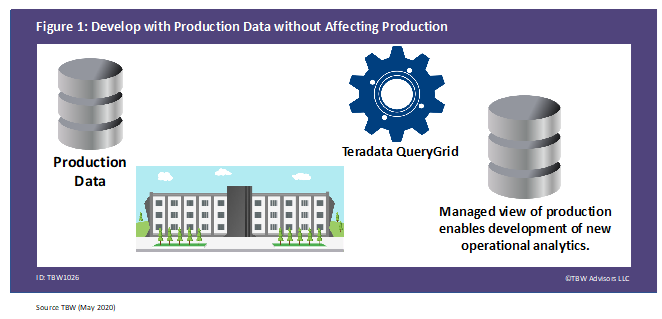
These Whisper Studies demonstrate two initial uses cases that prompted organizations to add data virtualization to their architecture. The first study involves a North American-based railroad’s evolution to Precision Railroading, which required entirely new operational metrics. To develop the metrics, the team required replica of production without affecting production. The railroad leveraged Teradata QueryGrid. The second study is from a consumer electronics manufacturer that wished to reduce its cost basis for data storage and computation. The original application did not require any changes. The manufacturer leveraged Gluent on Oracle and Hadoop to achieve their desired result.
The Studies
Railroad Access On-Premise Data
Scenario: Production data in Teradata – needed parallel dev environment
Start State: Production data in Teradata Active Enterprise Data Warehouse
End State: Teradata QueryGrid provides data access to dev environment
Data Size: 5 terabytes
Set-up Time: Half day to install, 6 months to optimize tuning
Interview(s): August 2019
Consumer Products Manufacturer to Lower Cost Performance Data Management
Scenario: Application leverage Oracle production database
Start State: Oracle storage growing too fast, too expensive
End State: Leveraged Gluent to evolve data and computations to Hadoop
Data Size: 31 terabytes of application data in Oracle Database
Set-up Time: One-hour installation, two months to implement
Interview(s): March 2020
Key Takeaways
Data virtualization is frequently brought into environments to provide access to production data without disturbing the production environment.
Data virtualization is frequently brought into environments to reduce the cost structure of an environment. Data virtualization is also useful in bringing legacy applications into a modern data management solution.
Set up for data virtualization is often quick; initial set up frequently takes less than a day, while most organizations become fluent in tuning the environment within 2-6 months.
These Whisper Studies center on two cases leveraging a data virtualization platform. In both scenarios, it is the organization’s first data virtualization use case or the one that caused them to add it to their architecture. The first study involves an organization that needed to update its operational models and related analytics. They needed to leverage production data to develop and confirm new metrics without disrupting production. The second Whisper Study wished to reduce the cost profile of their production and analytics without a major architecture change. Both leveraged data virtualization to address their needs.
Scenario: Production data in Teradata – needed parallel dev environment
Start State: Production data in Teradata Active Enterprise Data Warehouse
End State: Teradata QueryGrid provides data access to Dev
Data Size: 5 terabytes
Set-up Time: Half day to install, 6 months to optimize tuning
Interview(s): August 2019
A North American-based railroad company needed to move to new operational analytics as part of moving toward Precision Schedule RailRoading1. To accomplish this, the railroad wanted to evaluate the new operational metrics in development before updating production.
To evaluate the new metrics, the organization required a parallel environment to that of production. This parallel environment required some 30 tables and millions of rows of data – all without interrupting or burdening production. The data was primarily transportation data with some finance data mixed in.
To accomplish this, development needed an exact copy of the large volumes of production data. The copy needed to be scheduled, properly updated based on all dependent processes, and the development copy needed to be complete. In addition, to compare the new set of operational metrics to the current operational models, target tables of production were also required in the parallel environment.
Note that as a railroad is land rich with significant bandwidth available along the lines, the railroad owns and operates two of its own data centers. This also allows the organization to control the highly sensitive data regarding its operations that affect multiple industries, since they ship raw ingredients across the continent. As such, their entire solution is considered on-premise.
Because a majority of the data was in Teradata Active Enterprise Data Warehouse on-premise, it was natural to reach out to Teradata for a solution, which provided Teradata QueryGrid2, a data virtualization solution. Additional research that provides details on QueryGrid’s capabilities can be found in “Whisper Report: Six Data Engineering Capabilities Provided by Modern Data Virtualization Platforms.”
By leveraging QueryGrid, the railroad had a perfect replica of production without the concern of interfering with production. When using a data virtualization platform, the platform provides a view of the data to execute your needs. This view is independent of the original form of the data but may or may not actually involve an additional complete physical copy of the data. More importantly, the data virtualization technology is able to maintain an up to date view of the data, as depicted in Figure 1.
To leverage Teradata’s QueryGrid, the following steps were required.
Connect the source: As with all data layers, the specific sources to be used by the platform must be connected. When connecting the sources, the majority of the time was spent tracking down and setting up the permissions to connect.
Configure the views: Data virtualization platforms such as QueryGrid operate by providing data views. The second step was creating the required data views as required for the Precision Railroading Project.
To protect production, only official DBAs within IT could create views leveraging QueryGrid – they did not want production data to be wrongly exploited. No major problems were incurred by the project.
Figure 1. Develop with Production Data without Affecting Production
With the exact replica of production data and related current operational metrics, the railroad was able to perform a side-by-side comparison with the incoming Precision Railroading Metrics. It was critical for the business to get comfortable with the impact of the new metrics before they became the official operating metrics for the company. Accuracy was critical, as the railroad’s operational metrics are publicly released. Note, formal data validation platforms were not used to compare the data, but rather, SQL scripts were leveraged (see Whisper Report: Decision Integrity Requires Data Validation for related research).
The new corporate reporting metrics tracked events such as how long a train took to go from Point A to Point B, as well as how long the train stayed or stopped at each of the stations between the two points. Overall, there were an assortment of metrics that are part of the Precision Railroading that they wanted to realize. As a result of the new operational insights, they found numerous opportunities to make improvements in the process. For example, visibility was given to instances where certain customers required multiple attempts to successfully deliver a load. With the waste identified, the organization could now address issues that negatively impacted their efficiencies.
This project was the railroad’s first Teradata QueryGrid project. With success under their belt, the next project will expand the business’s ability to be more involved in self-service.
The second study involves a large electronics manufacturer seeking to reduce their cost profile. The electronics manufacturer has a large amount of sensor data coming from their machines (a single data set is 10 terabytes). The data regarding the machines is stored in an Oracle database, which worked well at first but was not able to maintain the cost profile desired by the organization. There was an annual expense for additional space required in order to continue leveraging the application storing information in Oracle. This organization wished to reduce the cost profile without rewriting the application.
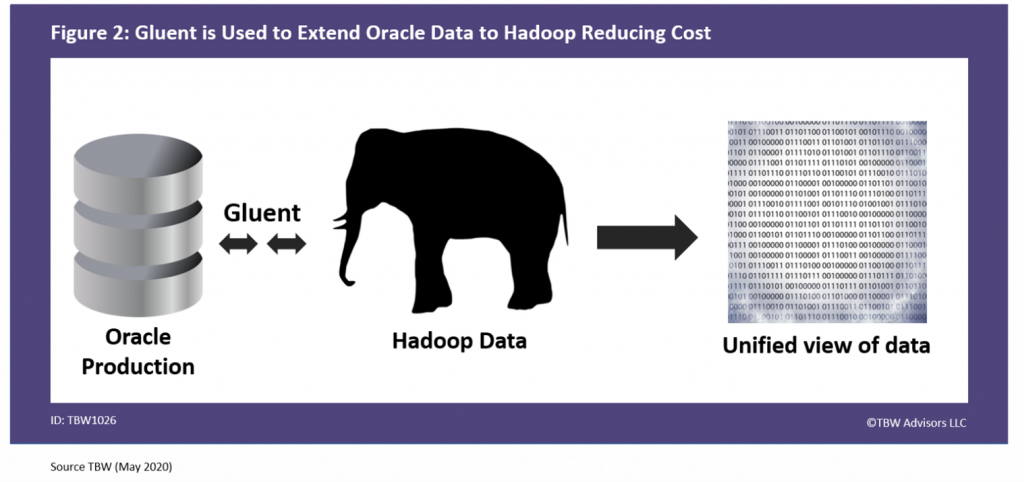
The consumer electronics manufacturer decided to leverage Gluent data virtualization solution3. Gluent was installed on the Oracle server and Hadoop. The application simply connected to Oracle without any changes whatsoever. Behind the scenes, the data and the work on the data was now spread between Oracle and Hadoop significantly reducing their cost structure and eliminating the need for the organization to expand their Oracle footprint. The fact that the data was spread between Oracle and Hadoop was invisible to the application and its users, as depicted in Figure 2.
In order to leverage Gluent the following steps were required.
Install Gluent: Gluent is installed on all data sources, particularly Hadoop and Oracle. When Oracle or Hadoop is called today, users are actually using the Gluent code installed on the server. The work is now able to be seamlessly offloaded to Hadoop as needed and is cost optimized. The install took less than one hour. Once again, it is critical to have access passwords available. Setting permissions correctly is also required.
Use the migration tool: Gluent has a built-in migration tool the consumer manufacturer was able to leverage to handle the initial set up. This automatically migrated some of the Oracle data to Hadoop while maintaining a single view of the data.
Query Tune: This is a continual effort that gets easier over time. When optimizations turn out to not be optimal, Gluent allows “Hints,” which are the methods one can design to optimize specific scenarios.
Figure 2. Gluent is Used to Extend Oracle Data to Hadoop Reducing Cost
The Oracle Applications still call on and use Oracle. Behind the scenes, Gluent installed on Oracle is able to leverage Hadoop for storage and compute power. The application itself did not require any changes. Their cost profile for data storage and computations is now reduced. The plan is to not change the Oracle application at all but, rather, to simply continue reducing the actual data and computations conducted by Oracle. Fortunately, this also moved this application group in line with other internal groups that are using big data solutions on Hadoop. The Hadoop environment is familiar to the other teams, and through Hadoop due to Gluent, those users can now leverage the Oracle application and related data without Oracle skills. This capability is due to two functionalities that are common in data virtualization.
Remote Function Execution: The ability of data virtualization to parse a query and have portions of a query executed on another remote system. In this instance, one can access Oracle and run the query on Hadoop. Likewise, one can access Hadoop and have a query run on Oracle. Where a query runs is subject to configuration and constraints such as cost and time.
Functional Compensation: The ability perform an Oracle operation, specifically SQL, on your Hadoop data, even though Hadoop does not support SQL queries natively.
Together, these two capabilities enable the manufacturer to leverage their Oracle experts without retraining. This benefit is in addition to reducing their storage and computational costs.
Data virtualization platforms have numerous benefits to organizations that add it to their architecture. This research examines five quantifiable advantages enterprises that adopt data virtualization experience. Quantifiable advantages include user access to data, copy data management, centralized governance, increased agility, and reduced infrastructure costs. Data Virtualization platforms provide measurable advantages to the digitally transformed and significantly contribute to the return on investment (ROI) realized by the architecture.
TDWI Las Vegas was an educational and strategy event for 425 attendees, including 66 international attendees from 15 countries. Four major educational tracks featured over 50 full day and half-day sessions, as well as exams available for credit on related courses to become a Certified Business Intelligence Professional (CBIP). The educational tracks included: Modern Data Management, Platform and Architecture, Data Strategy and Leadership, Analytics and Business Intelligence. The strategy Summit featured 14 sessions, including many case studies and a special session on Design Thinking. The exhibit hall featured 20 exhibitors and 6 vendor demonstrations and hosted lunches and cocktail hours.
TDWI Las Vegas was an educational and strategy event for 425 attendees, including 66 international attendees from 15 countries. Four major educational tracks featured over 50 full day and half-day sessions, as well as exams available for credit on related courses to become a Certified Business Intelligence Professional (CBIP). The educational tracks included: Modern Data Management, Platform and Architecture, Data Strategy and Leadership, Analytics and Business Intelligence. The strategy Summit featured 14 sessions, including many case studies and a special session on Design Thinking. The exhibit hall featured 20 exhibitors and 6 vendor demonstrations and hosted lunches and cocktail hours.
Modern data virtualization platforms are increasingly becoming a critical part of data architectures for the digitally transformed. Many data virtualization platforms provide data as a service, data preparation, data catalog, logically centralized governance, the ability to join disparate data sets, and an extensive list of query performance optimizations. Likewise, data virtualization platforms are increasingly being used to support six different and critically important use cases. This research evaluates and ranks the various modern data virtualization platforms according to their architectural capabilities and ability to successfully meet popular use cases.
When selecting technologies for your data architecture, it is important to understand common use cases enabled by the technology. This research examines six use cases enabled by data virtualization and the architecture capabilities used to support the use case. To this end, we examine the customer/enterprise 360 view of data that is also met by the logical data warehouse (LDW) architecture use case. We also evaluate the use cases of the large, hybrid multi-cloud environments, data lake acceleration, collaboration with external master data management (MDM) and data catalog solutions, managing Excel as well as application integration.